本文最后更新于 2025年8月8日 晚上
之前在一篇文章里简单研究了抽卡数据和流水排名间的关系,大致得出了流水和平均祈愿数有比较大的相关性。
简单分析下纳塔版本卡池的抽取数量和流水情况
如今丝柯克卡池已完全结束,数据相对稳定(但其实有未上传的玩家,数据还能有所增加)。但当时只考虑了角色池,没有考虑武器池,另外流水数据也主要使用了 iOS 排名,未考虑其他平台的流水。所以在此基础上,重新添加了武器池数据,并参考了 @天天背锅崩坏娘整理的每月流水数据。
其中武器池数据的 API 和角色池是一套体系,所以只要稍加修改代码,角色武器时间能对应上,就可以获得想要的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| import requests
import pandas as pd
import time
character_banner_ids = list(range(300070, 300085))
weapon_banner_ids = list(range(400069, 400084))
base_url = "https://api.paimon.moe/wish?banner={}"
all_data = []
for character_id, weapon_id in zip(character_banner_ids, weapon_banner_ids):
character_url = base_url.format(character_id)
weapon_url = base_url.format(weapon_id)
character_response = requests.get(character_url)
weapon_response = requests.get(weapon_url)
if character_response.status_code == 200 and weapon_response.status_code == 200:
character_data = character_response.json()
weapon_data = weapon_response.json()
character_total = character_data.get("total", {})
weapon_total = weapon_data.get("total", {})
character_pull_by_day = character_data.get("pullByDay", [])
weapon_pull_by_day = weapon_data.get("pullByDay", [])
first_character_pull_by_day = character_pull_by_day[0] if character_pull_by_day else {}
first_weapon_pull_by_day = weapon_pull_by_day[0] if weapon_pull_by_day else {}
current_data = {
"character_banner_id": character_id,
"角色祈愿日期": first_character_pull_by_day.get("day"),
"weapon_banner_id": weapon_id,
"武器祈愿日期": first_weapon_pull_by_day.get("day"),
"角色祈愿总数": character_total.get("all"),
"角色玩家总数": character_total.get("users"),
"角色首日祈愿数": first_character_pull_by_day.get("percentage") * character_total.get("all"),
"角色平均祈愿数": character_total.get("all") / character_total.get("users"),
"武器祈愿总数": weapon_total.get("all"),
"武器玩家总数": weapon_total.get("users"),
"武器首日祈愿数": first_weapon_pull_by_day.get("percentage") * weapon_total.get("all"),
"武器平均祈愿数": weapon_total.get("all") / weapon_total.get("users"),
"祈愿总数": character_total.get("all") + weapon_total.get("all"),
"首日祈愿数": first_character_pull_by_day.get("percentage") * character_total.get("all") + first_weapon_pull_by_day.get("percentage") * weapon_total.get("all"),
"平均祈愿数": (character_total.get("all") + weapon_total.get("all")) / character_total.get("users")
}
all_data.append(current_data)
print(f"卡池 ID {character_id} 和 {weapon_id} 的数据已成功提取")
else:
print(f"请求失败,卡池 ID:{character_id} 或 {weapon_id},状态码:{character_response.status_code} 或 {weapon_response.status_code}")
time.sleep(5)
df = pd.DataFrame(all_data)
output_file = "wish_data_summary.xlsx"
df.to_excel(output_file, index=False)
print(f"所有卡池的数据已成功保存到 {output_file}")
|
此外,为了整合角色卡池和武器卡池的抽取数据,额外计算了祈愿总数(角色祈愿数+武器祈愿数)、首日祈愿数(角色首日祈愿数+武器首日祈愿数)和平均祈愿数(祈愿总数/角色玩家总数)。其中平均祈愿数考虑到抽角色和抽武器的玩家有重叠,分母仅使用了角色的玩家数。
崩坏娘的收入数据按照月统计,时间跨度有所区别。这里以卡池首日日期所在月份为基准,做了预估处理,如果两个卡池同属一个月份,则两个卡池预估收入记作一样。尽管有些不合理,但暂时没有什么好的方法。
原始数据如下:
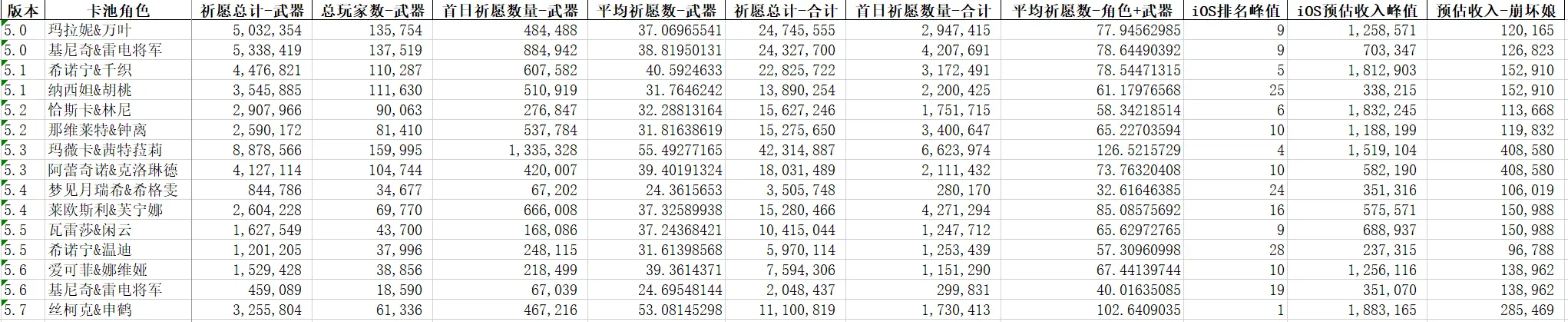
对收集到的数据两两相关性分析后,得到相关性矩阵,重点观察抽卡数据和后三个流水数据的相关性:

除了某麦强自相关的排名和预估收入,其他相关性最高的数据都落在武器的平均祈愿数上,另外角色的平均祈愿和总平均祈愿上相关性也不差。
一般相关系数绝对值 0.5-0.8 表示已经存在中等强度的线性关系,武器平均祈愿数达到 0.7 以上已经算是较强的相关性了。不过武器卡池的数据具有最强相关性也是略微出乎意料,原来看流水还得看平均每个玩家抽了多少武器,武器池才是真正拉动流水差异的根源。
另外,某麦上的流水数据和崩坏娘统计的预估收入的相关性整体较弱,比不上平均祈愿指标,所以之后的分析可能会不再收集某麦的预估收入数据了。
考虑到一个月双卡池相同预估流水的干扰,删除部分卡池(流水较差、主要是纯老角色复刻池)后再做一次相关性分析。

可以看到和崩坏娘预估收入强相关的几个平均祈愿数的相关系数再次拉高,接近 0.9 水平,可以说是强线性相关了。其中武器平均祈愿数再次获得最高相关性。
经过本次补充数据提取和分析,可以完善一些之前得到的结论。
比如虽然整体玩家数在下降,但流水并没有呈现出明显的同步下降趋势。 有可能流失的是靠着游戏内免费资源抽卡的玩家(或者是玩家懒得上传抽卡数据了,或者新的玩家并不知道这个平台导致一些数据缺失),对流水的影响不大,所以几个玩家数和流水的相关性都比较弱。
再比如平均祈愿数这一指标确实有用。平均祈愿数越高,越能反映在消耗掉库存原石后,整体玩家氪金水平,尤其是武器池的平均祈愿数。
后续的分析计划可以考虑把枫丹的数据也拉出来分析下,或者考虑如何把卡池数据和月流水数据进行对齐,再之后通过抽卡数据建模预估卡池流水。