基于概率方法的Excel数据构造方法
本文最后更新于 2025年6月30日 晚上
起因是工作中突然接到了一个需求,需要模拟一些数据。
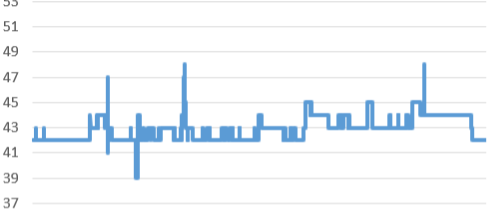
原始数据大约有 10000+的数据量,从可视化结果上大致可以得出特征:
- 数据比较稳定,偶有一些波动;
- 大体上呈现一定的上升趋势,但上升速度比较缓慢,总体也就增长了 1、2 这样。
需求:保持数据的整体特征不变,但末尾呈现更加明显的增长趋势。
本来想着开 vscode 写 python 代码了,突然一想有点麻烦,不如在原来的 excel 里试一试。
当然如何在 excel 里造这样的数据,我也毫无思路,于是果断问起了大模型。
excel 生成范围内随机自然数,多个连续自然数有较好的连续性,不会随意上下变动。
大模型首先给出了 RANDBETWEEN 函数,但是这个函数相邻数据间的波动过于频繁,显然与原始数据模式不同。

于是追问:
这样前一个数和后一个数可能都会不同,能不能提高前后数值的一致性,一个数连续出现几次,然后再随机变成另一个数。
大模型又给出了新的方案,通过构造一个计数器的中间值,当中间值满足计数条件的时候,再对上一个数值进行变动处理。
仔细看了下大模型的输出,虽然细节上有点问题,但整体思路 ok,于是照着这个流程开始试验。
第一步,生成一列随机数,使用 RANDBETWEEN 函数生成 1-100 的随机数。
第二步,计算变化量列,当随机数那一列的值达到某种规则的时候,对应的变化量为-1,0 或 1。由于我的要求是相对快速上升,于是大致定了随机数为 1 的时候,变化量为-1;随机数为 99、100 的时候,变化量为 1;其余为 0。翻译一下,就是 2%概率+1,1%概率-1,97%不变。其中转化过程使用 IFS 函数:IFS(A1>=99,1,A1<=1,-1,AND(A1>1,A1<99),0)。
第三步,用上一个值+变化量构造目标数据。
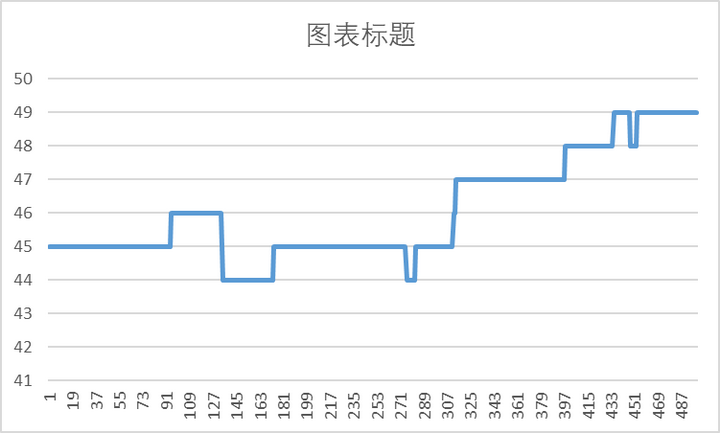
最终模拟了 500 个数据,从结果上看和原始数据的特征大体一致。值得注意的是,随机结果具有不稳定性,且 500 个数据量也不是特别大,可能需要多次尝试并找到合适的结果。
本文重在介绍思路,很多数据构造的需求完全可以由 excel 来实现。比如在此基础上,可以调整波动范围(IFS 函数多设置几个条件,概率也可以调整),直至生成自己满意的数据。