简单分析下纳塔版本卡池的抽取数量和流水情况
本文最后更新于 2025年7月25日 晚上
前段时间《原神》丝柯克卡池在 618 期间力压抖音登顶。时隔一年多再次登顶(上一次是仆人首次 UP 卡池),引发了社区的热议。
当时简短发了个想法,大致意思就是虽然登顶有些出乎意料,但从整体数据上而言并比不上火神卡池,618 的抖音也并没有想象中那么强。
如今丝柯克卡池已经进入尾声阶段,各阶段数据也相对稳定,是时候结合一下纳塔版本的卡池,做一些更系统的分析了。
分析思路
以 https://paimon.moe/抽卡记录网站的数据为主进行分析,结合某麦 iOS 上的排名、收入预估数据做一下相关分析。
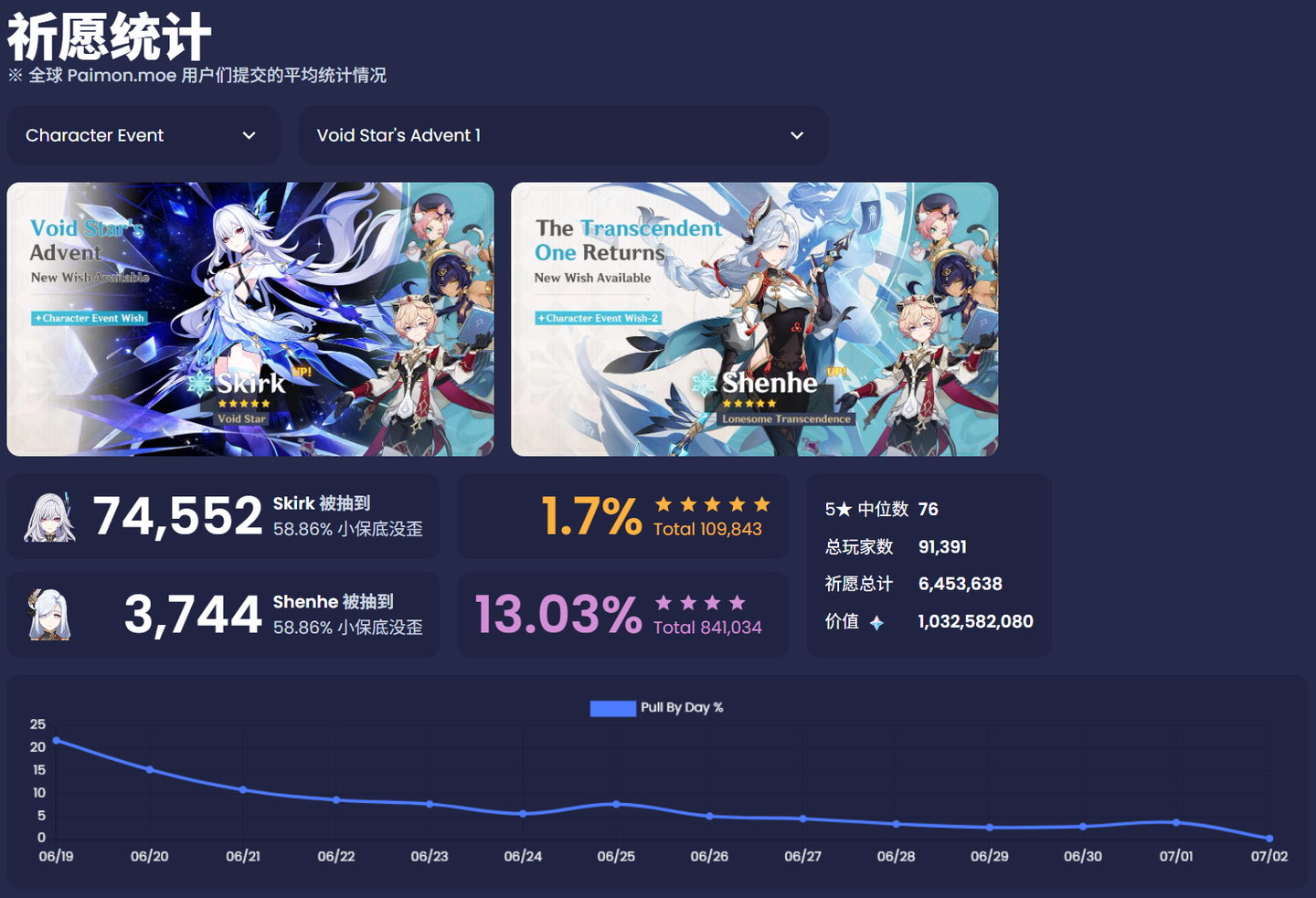
其中抽卡数据主要关注每一个角色卡池(武器卡池先不管,有机会之后补充)的抽卡总数、玩家数量、首日抽卡数量。抽卡总数和玩家数量都比较好理解;首日抽卡数量往往意味着抽卡和充值的高峰期,会影响排名峰值和收入峰值;另外也简单计算了下平均每个玩家抽卡数量,理论上平均抽卡数量越高,角色命座抽得越高,更有可能提升排名。
某麦上的数据只是简单做个目标的参考,其中排名的参考价值稍大一些(但也会受到其他竞品的互相影响,结果并不绝对),收入预估平台有自己的算法策略这里我不做太多评价。
分析的主要目标是观察以上这些指标在纳塔版本的历次卡池的情况,目前一共 15 个卡池,数据量也不大。
数据获取
简单分析下派蒙的数据来源,得到数据大致由以下 API 进行获取:
其中 banner 后的数字代表卡池 id,于是通过和大模型的交流,快速得到了一段爬虫代码,将想要保存的数据整合到了 Excel 中。
1 | |
至于某麦的数据,懒得写代码了,直接人工记录下。
最终顺利得到如下的数据表:
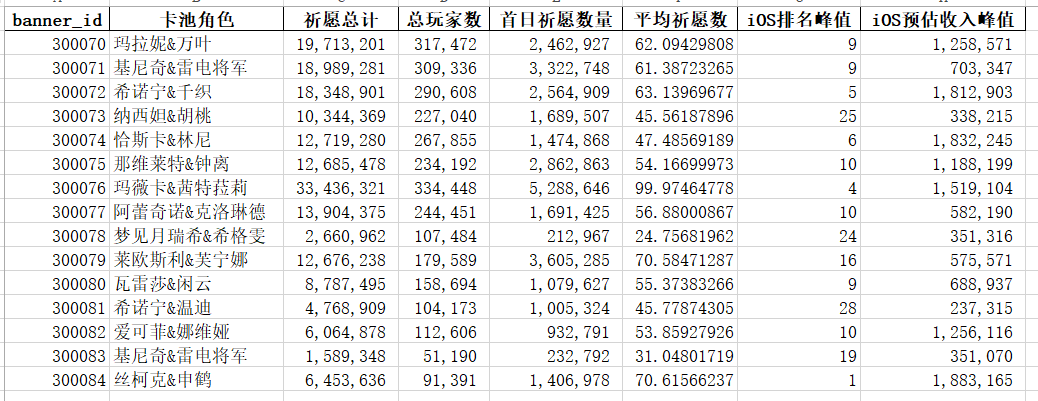
由于丝柯克卡池还未结束,估计还有不少人没有上传数据,最终祈愿总数和总玩家数还有一些提升空间。
数据分析
简单看下数据表中的数据,不难发现火神卡池在祈愿总数、首日祈愿数量、平均祈愿数指标上都呈现出断崖式的领先。神池+高人气角色奶奶的双重加持,并不意外,毕竟原的玩家对神池的执念就摆在那里。超抖 33h 的成绩也侧面印证了这一点,只是可惜元旦期间腾讯三剑客过于强大,遗憾败北。
其余的话,纳塔版本初期整体数据较为亮眼,后期相对平庸。刨除复刻角色,后期的三个新角色瓦雷莎、爱可菲、丝柯克祈愿总数都没超过 1千万。玩家数量上也从前期的二三十万到最近的不足 10 万,玩家流失,或者说记录抽卡的玩家流失很严重。
首日祈愿和平均祈愿数上来看,下降趋势倒也稍微缓和了些。丝柯克卡池首日祈愿上还能和初期的恰斯卡卡池一打,平均祈愿上更是力压一种纳塔角色,仅次于火神。说明遗留的玩家更可能在首日进行抽卡,且抽高命座的可能性更高。
但是如果总体玩家在减少,剩下的玩家就算平均抽取量高,想要获得好的流水也是难上加难。所以本次丝柯克卡池虽然登顶,但只超抖 12h,不如火神,其他数据层面也不如火神,很难说是一件值得开香槟的事。
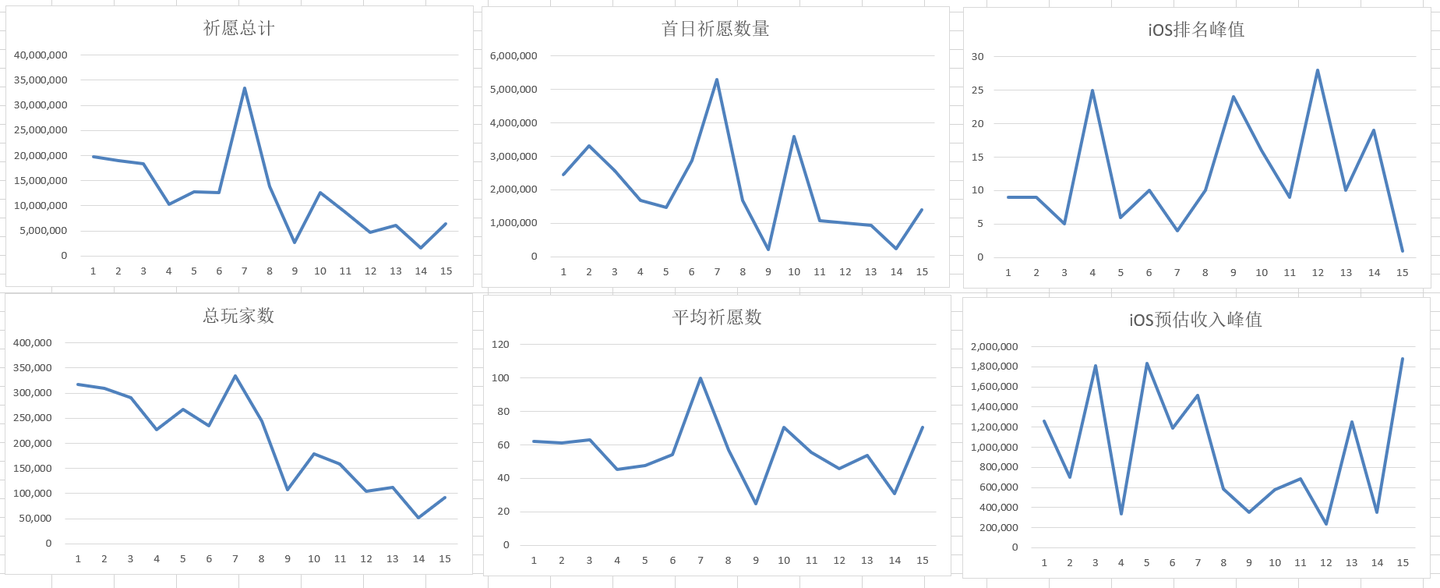
结合可视化结果,得出的结论也大致相似,数据量很少,可视化只是在直观性上更明显了一点。
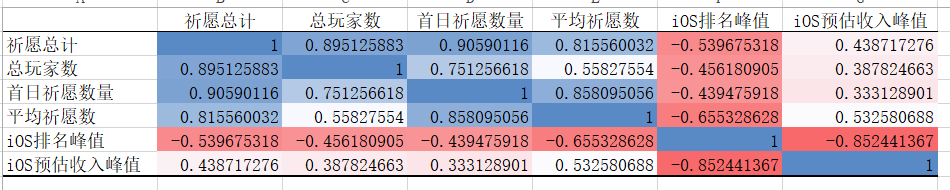
最后做个相关性分析,抽卡网站内获取的四个指标相互间相关性都较高;而排名峰值和其他指标呈现明显的负相关,倒也十分合理,毕竟抽的越多,排名数值越小。
某麦的预估收入算法估计和排名挂钩,呈现出最大的负相关性。而除掉这个内部因素,排名和平均祈愿数的负相关最大,也验证了之前这一指标提出时的假设。回到丝柯克卡池,平均 70 多的祈愿数,造就了一个短期的登顶,也算是一个合理的结果,很可能是氪佬玩家哐哐砸满命的结果。
总结
虽然丝柯克卡池登顶,但是玩家流失的问题显然更严重,不要被一时的登顶蒙蔽背后的真相,也不要忘记巅峰时期随便一个卡池的登顶成绩都比如今的好很多。
结合最近频出的高难活动,我确实觉得原在抽卡引导上有一些变味。我最初的评价是 pay to love 模式,这在早期版本确实如此。可如今已经更倾向于强度党的 pay to win 模式,尽管没有 pvp 对战,win 的都是策划的数值还有排行榜。
最后,数据分析往往都是片面的,比如本次我就没有考虑武器池,芙宁娜卡池平均祈愿数也很高但排名很差(很可能是氪佬已经满命,爆发量不足)。
有机会的话,可以考虑找到更合适的指标。